Changelog:
| August 13, 2007: | Slashdotted! |
| August 22, 2007: | Fixed bugs with "extreme" links in some wiki text |
| September 9, 2007: | Introduced extra script to install the templates used by a page (improves rendering of some pages) |
| September 17, 2007: | It appears that woc.fslab.de (the site offering the standalone wiki renderer) is down. Until they come back up, you can download the latest snapshot of the renderer here. |
| October 21, 2007: | I found an article whose wiki text caused the woc.fslab.de parser to abort - modified show.pl to use the plain wiki content in that case. |
| March 31, 2008: | Robin Paulson notified me that the same process can be used to install Wiktionary offline! |
| April 10, 2009: | Ivan Reyes found out why some wiki texts caused the woc.fslab.de parser to fail, mediawiki_sa.tar.7z updated. Thanks, Ivan! |
| September 9, 2009: | Meng WANG made some modifications for searching in the Chinese (and probably other non-English) wikipedias. |
| September 19, 2009: | James Somers added caching of LaTEX-made images. His patch is available here. |
| November 6, 2009: | The woc.fslab.de repository is apparently no longer accessible... I also found out that PHP now has "namespace" as a keyword, and that the old fslab.de tarball has PHP code that uses a "class Namespace". I therefore patched it to make it work with today's PHP interpreters (the updated woc.fslab.de tarball is here). |
Executive summary
It's strong points:- Very fast searching
- Keyword (actually, title words) based searching
- Search produces multiple possible articles: you can choose amongst them
- LaTEX based rendering for Mathematics (thanks to the guys at woc.fslab.de)
- Harddisk space is minimal: the original .bz2 file (split in pieces) plus the index built through Xapian
- Orders of magnitude faster to install (a matter of hours) compared to loading the "dump" into MySQL
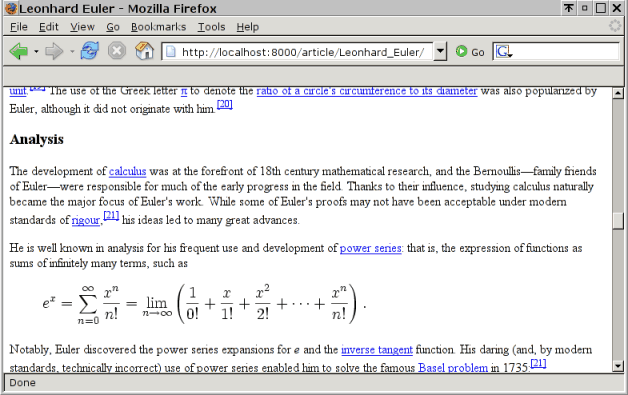
What this is and why I built it
Wikipedia needs no introductions: it is one of the best - if not the best - encyclopedias, and it's freely available for everyone.Everyone can be a relative term, however... It implies availability of an Internet connection. This is not always the case; for example, many people would love to have Wikipedia on their laptop, since this would allow them to instantly check for things they want regardless of their location (business trips, hotels, firewalled meeting rooms, etc). Others simply don't have an Internet connection - or they don't want to dial up one every time they need to look something up.
Up to now, installing a local copy of Wikipedia is not for the faint of heart: it requires a LAMP or WAMP installation (Linux/Windows, Apache, MySQL, php), and it also requires a tedious - and VERY LENGTHY procedure that transforms the "pages/articles" Wikipedia dump file into data of a MySQL database. When I say *lengthy*, I mean it: last time I did this, it took my Pentium4 3GHz machine more than a day to import Wikipedia's XML dump into MySQL. 36 hours, to be precise.
The result of the import process was also not exactly what I wanted: I could search for an article, if I knew it's exact name; but I couldn't use parts of the name to search; if you don't use the exact title, you get nothing. To allow these "free-style" searches to work, one must create the search tables - which I'm told, takes days to build. DAYS!
Wouldn't it be perfect, if we could use the wikipedia "dump" data JUST as they arrive after the download? Without creating a much larger (space-wise) MySQL database? And also be able to search for parts of title names and get back lists of titles with "similarity percentages"?
Follow me...
Identifying the tools
First, let's try to keep this as simple as possible. We'll try to avoid using large, complex tools. If possible, we'll do it using only ready made tools and scripting languages (Perl, Python, PHP). If we need something that runs fast, we'll use C/C++.What do we need to pull this through?
- The "pages/articles" dump file
Right now (August, 2007) the file is a 2.9GB download, always available from here. I set this to download overnight at my work, using wget and rate-limiting it to 80KB/sec - to keep my sysadmin at ease. It downloaded in 10 hours - I proceeded to burn it to a DVD and brought it back home.
- Parsing the dump
This file is just a big XML file - parsing it, through any SAX parser is child's play. We basically only care about two elements, title and text: This command for example...bash$ bzcat enwiki-20070802-pages-articles.xml.bz2 | head -10000 | \ grep -A 100 '<title>Anarch' | less... shows a piece of the data we need to parse:<title>Anarchism</title> <id>12</id> <revision> <id>149030244</id> <timestamp>2007-08-03T23:24:05Z</timestamp> <contributor> <username>Jacob Haller</username> <id>164072</id> </contributor> <comment>/* Four monopolies */</comment> <text xml:space="preserve">{{dablink|"Anarchist" redirects here. For the comic book character, see [[Anarchist (comics)]].}} {{toolong}} {{disputed}} {{Anarchism}} '''Anarchism''' is a [[political philosophy]] or group of philosophiesWe basically need to work with the <title> and the <text> contents; that's all the viewer will need: search using the title (and parts of it), and watch the data of the <text> section.This XML format is in fact so simple to parse, that we don't even need a full-blown SAX parser: we can do it via regular expressions: search for <text>, and keep reading until we meet </text>.
- Seeking in the dump file
Hmm... We would certainly prefer not to use MySQL or any other database, since we are only *reading* Wikipedia, not writing into it. If only we could seek inside this huge .xml.bz2 file...Turns out we can do something VERY close: we can use the bzip2recover tool (part of bzip2 distribution) to "recover" the individual parts of this compressed file: Basically, BZIP splits its input into 900K (by default) size blocks, and compresses each of them individually. bzip2recover seeks out a "magic" signature that identifies the beginning of each block, and dumps each block it finds as an individual "recNumberOriginalname" file.
What this means, in plain English, is that we can convert the huge downloaded .bz2 file to a large set of small (smaller than 1MB) files, each one individually decompressible! This process is fast (since it involves almost no CPU calculations - it took 20min on my Pentium4 3GHz) and doesn't waste space: you can remove the original 2.9GB file when bzip2recover completes. The generated files (13778 in my case) occupy equal space: 2.9GB.
(Note: to answer to some Slashdot readers, yes, of course we have to take into account that a <text> section might be split across "block-boundaries" and that our "decoding" scripts must account for that; as for the possibility of the element names (i.e. <text> or <title> being split, it is non existent - compressing algorithms always take repetitions into account, and store references to previous appearances instead of the original texts themselves - since the element names appear all the time, they will not be split - hopefully :‑)
- Building a search index
All we need to do, is to use the words in the title as an "index" to the text. We basically want to associate each title (and its words), with the small .bz2 file it belongs in! Searching for the specific title inside the small .bz2 file will take almost no time - it will decompress in less than half a second, since it is very small!How do we associate a set of words with a "target"? We need a custom search engine... Looking around for an open-source search engine proved fruitful immediately: Xapian is a blindingly-fast, simple to use C++ engine. It took me 20 minutes to look in the code of its examples, and I quickly realized that this code fits the profile!
This code is based on one of the Xapian examples, one that creates a search index: it is augmented here to start from titles (and their words, created by function Tokenize) and provide the filename of the bzip2 block file that contains them. The code expects to read standard input like this:/* quickstartindex.cc: Simplest possible indexer */ #include <xapian.h> #include <iostream> #include <string> #include <vector> #include <cctype> #include <algorithm> using namespace std; #define MAX_KEY 230 #define SPLIT_TITLE_INTO_KEYWORDS // Split a string into its tokens, based on the given delimiters void Tokenize(const string& str, vector<string>& tokens, const string& delimiters) { // Skip delimiters at beginning. string::size_type lastPos = str.find_first_not_of(delimiters, 0); // Find first "non-delimiter". string::size_type pos = str.find_first_of(delimiters, lastPos); while (string::npos != pos || string::npos != lastPos) { // Found a token, add it to the vector. tokens.push_back(str.substr(lastPos, pos - lastPos)); // Skip delimiters. Note the "not_of" lastPos = str.find_first_not_of(delimiters, pos); // Find next "non-delimiter" pos = str.find_first_of(delimiters, lastPos); } } // We will perform case insensitive searches, // so we need a function to lowcase() a string char to_lower (const char c) { return tolower(c); } void lowcase(string& s) { transform(s.begin(), s.end(), s.begin(), to_lower); } int main(int argc, char **argv) { unsigned total = 0; try { // Make the database Xapian::WritableDatabase database("db/", Xapian::DB_CREATE_OR_OPEN); string docId; while(1) { string title; if (cin.eof()) break; getline(cin, title); int l = title.length(); if (l>4 && title[0] == '#' && title.substr(l-4, 4) == ".bz2") { docId = title.substr(1, string::npos); continue; } string Title = title; lowcase(title); // Make the document Xapian::Document newdocument; // Target: filename and the exact title used string target = docId + string(":") + Title; if (target.length()>MAX_KEY) target = target.substr(0, MAX_KEY); newdocument.set_data(target); // 1st Source: the lowercased title if (title.length() > MAX_KEY) title = title.substr(0, MAX_KEY); newdocument.add_posting(title.c_str(), 1); vector<string> keywords; Tokenize(title, keywords, " "); // 2nd source: All the title's lowercased words int cnt = 2; for (vector<string>::iterator it=keywords.begin(); it!=keywords.end(); it++) { if (it->length() > MAX_KEY) *it = it->substr(0, MAX_KEY); newdocument.add_posting(it->c_str(), cnt++); } try { //cout << "Added " << title << endl; // Add the document to the database database.add_document(newdocument); } catch(const Xapian::Error &error) { cout << "Exception: " << error.get_msg(); cout << "\nWhen adding:\n" << title; cout << "\nOf length " << title.length() << endl; } total ++; if ((total % 8192) == 0) { cout << total << " articles indexed so far" << endl; } } } catch(const Xapian::Error &error) { cout << "Exception: " << error.get_msg() << endl; } cout << total << " articles indexed." << endl; }
#rec00001enwiki-20070802-pages-articles.xml.bz2 AlgeriA AmericanSamoa AppliedEthics AccessibleComputing Anarchism AfghanistanHistory AfghanistanGeography AfghanistanPeople AfghanistanEconomy ... ... Topics of note in Atlas Shrugged Atlas Shrugged #rec00002enwiki-20070802-pages-articles.xml.bz2 Anthropology Archaeology Anomalous Phenomena ...
...which is easily generated with this script:bash$ echo Enter the directory of the recXXXXX...bz2 files bash$ cd wiki-splits bash$ echo Create the index directory bash$ mkdir db bash$ echo Building the index bash$ for i in rec*.bz2 ; do echo \#$i bzcat $i | grep '<title' | \ perl -ne 'm/<title>([^<]+)<\/title>/ && print $1."\n";' done | ../quickstartindex
Indexing with Xapian will take some time, depending on the speed of your CPU and the number of cores you have. Expect at least a couple of hours (my single core Pentium4 3GHz took 5 hours to build it).Using the Xapian provided quickstartsearch example application, we can now do this:
bash$ ./quickstartsearch db/ greece 99% [rec00124enwiki-20070802-pages-articles.xml.bz2:Greece] 72% [rec00137enwiki-20070802-pages-articles.xml.bz2:Hellenic Greece] 72% [rec00465enwiki-20070802-pages-articles.xml.bz2:Argos, Greece] 72% [rec00468enwiki-20070802-pages-articles.xml.bz2:Marathon, Greece] 72% [rec00524enwiki-20070802-pages-articles.xml.bz2:Athens, Greece] 72% [rec00583enwiki-20070802-pages-articles.xml.bz2:Thebes, Greece] ...
Perfect...! Seems to be working!
And it didn't require a WEEK to build!
- Showing the wiki markup as nice HTML
Fortunately, I can rely on others for this: the nice people over at woc.fslab.de have created a standalone wiki-markup parser which is ready for use! Checking out their code with Subversion...bash$ svn co https://fslab.de/svn/wpofflineclient/trunk/mediawiki_sa/ mediawiki_sa
...allows a quick test:bash$ cd mediawiki_sa bash$ php5 testparser.php bonsai.wikimarkup > bonsai.html
Nice and simple.(Update, September 17, 2007: It appears that woc.fslab.de (the site offering the standalone wiki renderer) is down. Until they come back up, you can download the latest snapshot of the renderer here.)
- Orchestration
Now we have all the ingredients: we need to "cook" them together, and what better way to do this than to use a simple Web front-end (no, NOT a full blown Apache!). We can do this in Perl or Python or whatever... I started with a simple, standalone script in Perl:bash$ ./mywiki.pl Usage: ./mywiki.pl keyword1 <keyword2> ... bash$ ./mywiki.pl greece 0: (abort) 1: (99%) Greece 2: (72%) Hellenic Greece 3: (72%) Argos, Greece 4: (72%) Marathon, Greece 5: (72%) Athens, Greece ... Select a number: 2 (firefox starts up, showing the generated HTML file)
This won't suffice, though. One of the reasons people morph into Wikipedians is because they can jump from one article to the next, following the hyperlinks. I built a mini-server (in Python, using Django) to accomplish this. You can of course build your own, since the work is indeed too easy... (you can even use CGI to invoke the standalone Perl script). In Django, it only took 80 lines of Python code in the scaffolding to support keyword based searching, choosing one article out of the many possibilities offered by 'quickstartsearch', adding a 'search' bar on top of all article pages, etc...
Anyway, I think I'll stop here. Make sure you have Python, Perl, Php (the big hammers), Xapian and Django (the small ones), install this package, and you will be able to enjoy the best (currently) possible offline browsing of Wikipedia. Just untar it, type 'make' and follow the instructions.
Version wise - some people asked this - I used the following (but since I am only using simple constructs, I believe other versions will work just fine): Perl 5.8.5, Python 2.5, PHP 5.2.1, Xapian 1.0.2 and Django 0.9.6.
Update, September 9, 2007: Some of the pages appear less appealing than what they can - they use wiki templates, which are not installed in woc.fslab.de's renderer by default. These templates are, however, inside the .bz2 files - all we need to do is install them in the renderer. If you meet such a page, execute fixTemplatesOfCurrentPage.pl from within the installation directory: the script (part of the package) will read the data of the last page shown, and install the necessary templates in the renderer. Simply refresh your browser, and the templates will then be rendered correctly.
Update, September 17, 2007: It appears that woc.fslab.de (the site offering the standalone wiki renderer) is down. You can download the latest snapshot of the wiki renderer here, so comment out the subversion checkout command from the Makefile, and just untar this instead.
Update, October 21, 2007: I found an article whose wiki text caused the woc.fslab.de parser to abort - modified show.pl to use the plain wiki content in that case.
Update, March 31, 2008: According to Robin Paulson, the same process described here also works for Wiktionary. I didn't even know there was a Wiktionary!... Thanks, Robin!
Update, February 27, 2012: It is now almost 5 years since I published my technique for offline Wikipedia browsing... Other methods have surfaced in the meantime, and people from the Wikimedia foundation asked me to add a link to Kiwix: an ongoing effort to create an easy to install, open-source, offline Wikipedia reader. Looks interesting...
P.S. Isn't the world of Open Source amazing? I was able to build this in two days, most of which were spent
searching for the appropriate tools. Simply unbelievable... toying around with these tools and writing less than 200
lines of code, and... presto!


| Index | CV | Updated: Sun Oct 22 14:41:45 2023 |